4.1 Models
The table below lists the different generations of OpenAI GPT models.
Standard context windows: gpt-3.5 (4K), gpt-4 (8K), gpt-4o (8K). For more info, see GPT models documentation.
Modality refers to the types of inputs that the model can process such as text and images. This highlights the versatility of the model in handling different kinds of data. Cost_input and Cost_output is the cost of input and output in USD per million tokens. Context_max indicates the maximum length of the text (in tokens) that the model can consider. Larger context windows allow the model to take into account more information when generating responses. Intelligence is a relative score of the model’s capabilities. Speed is a relative score of the rate at which output tokens are generated. Mini models are generally faster but lower intelligence. Date_training shows the cutoff date for the data used to train the model. It indicates how up-to-date the model is in terms of general knowledge.
The table below lists the different variants usually available for a model.
| Model | Description |
|---|---|
| gpt-3.5 | Standard model |
| gpt-3.5-turbo | Optimized for speed & cost, for rapid interactions such as chat |
| gpt-3.5-16k | Extended context window of 16K tokens |
| gpt-3.5-instruct | Fine tuned to follow instructions more accurately |
| gpt-3.5-preview | Experimental early release |
The instruct or turbo versions are recommended for chat use.
4.2 Parameters
Let’s explore some of parameters that affect the responses from an OpenAI model.
4.2.1 Temperature
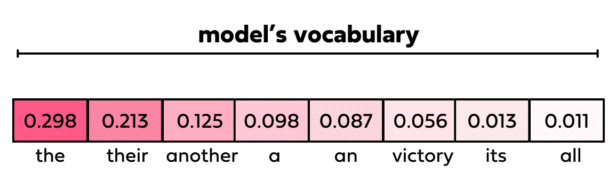
- Controls randomness/creativity, Range 1-2
- Close to 0: Deterministic and predictable, For factual responses
- Default 1: Balanced
- Close to 2: More random, diverse, for brain storming, story telling etc.
4.2.2 Top P (Nucleus sampling)
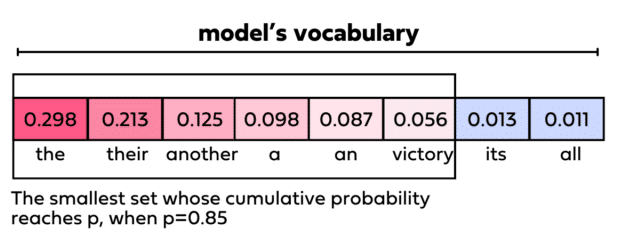
- Limits output by selecting top tokens up to cumulative probability P
- Range 0-1
- Default 1: Broader range of tokens considered, more variance, creative writing
- Lower values: Fewer tokens considered, more focused, consistent text
4.2.3 Frequency penalty
- Penalizes frequent tokens to reduce repetition in generated text
- Range -2 to 2, Default 0
- >0: Avoid repeating words or phrases. Output more varied but potentially less cohesive, more creative writing
- <0: Repeat words/phrases more often, more coherent but risk of redundancy. Technical writing
4.2.4 Presence penalty
- Encourages new concepts by penalizing previously used tokens
- Range -2 to 2, Default 0
- >0: Likely to introduce new topics making the output diverse and wide-ranging
- <0: Less compelled to introduce new topics, maintain focus on a specific subject. Good for detailed explanations, essays, instructions